how AlphaGO Zero works
The Key idea of AlphaGO Zero is to basically shoehorn a neural network into the MCTS value function. In solving_TicTacToe_with_MCTS I talked about how this plays out. The code gimmick in MCTS is we randomly sample until we have a decent idea on which node is most likely the better move, the case of TICTACTOE, the game is MCTS perfect, so it will always give the best move.
The MCTS value function, UCT was defined as follows,
the updated function is called PUCT, defined as the following,
By convention, this new formula's Q is already the mean
# vannila MCTS
Q = Q_sum / N
# PUCT convention
Q_new = (N_old * Q_old + v_leaf) / (N_old + 1)
\(c\) still represents the same constant as before, but the new trick here is the \(P\)
The Neural Network
The code is of AlphaGo is there will be a neural network learning the evaluate position, it will take the current board state as input and spit out the policy and value, the policy will be used for compute \(PUCT\) while \(v\) will reveal the predicted game outcome. The game state will be the input, since we dont rely on Heuristic solutions, we need to provide the network as much as we can for it to work.
The neural network structure
-
shared feature extractor
-
two output heads:
-
policy head → action probabilities
-
value head → game outcome
-
Input Shapes
For the game of Baghchal let us construct a structure for the board.
\([C,\;5,\;5]\)
Where C = number of feature planes.
| Plane | Meaning |
|---|---|
| 0 | Tiger positions (1 where tiger exists) |
| 1 | Goat positions |
| 2 | Player to move (1 = Tiger, 0 = Goat) |
| 3 | Phase flag (1 = placement, 0 = movement) |
| 4 | Goats remaining to place (normalized scalar plane) |
The feature extractor
Input [C,5,5]
Conv2D(256, 3×3, padding=same)
BatchNorm
ReLU
Residual Block × N (typically 10–20 for small boards)
So from Input->Convolution->Batch Normalization
Residual block
This section will have more convolutions and batch normalizations. The output shape should be \([256, 5, 5]\)
Policy and value heads
Conv2D(2, 1×1)
BatchNorm
ReLU
Flatten
Dense(|A|)
With this we finally get the policy.
And value.
Conv2D(1, 1×1)
BatchNorm
ReLU
Flatten
Dense(128)
ReLU
Dense(1)
Tanh
The shared ResNet trunk will split into the policy and value head. now we run simulations with the MCTS and train this network and hope it learns to play the game.
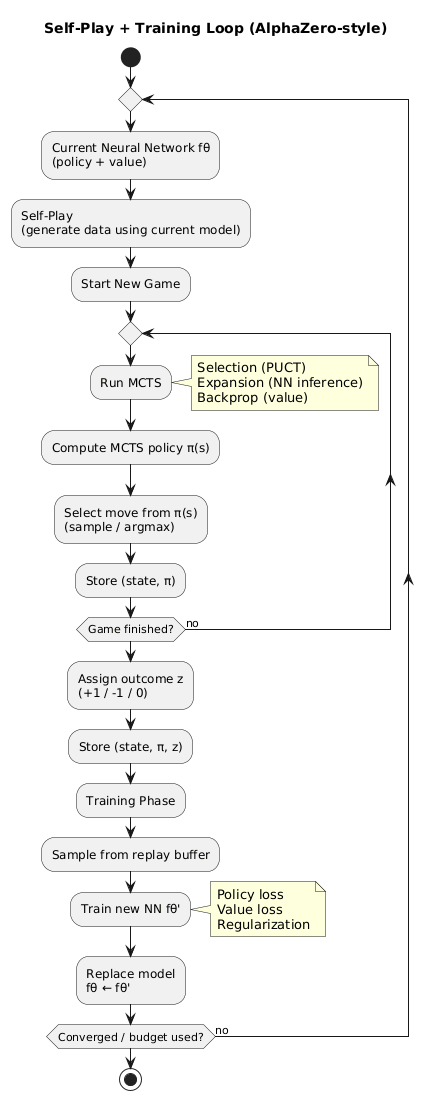
A visual representations of how the training flow happens.